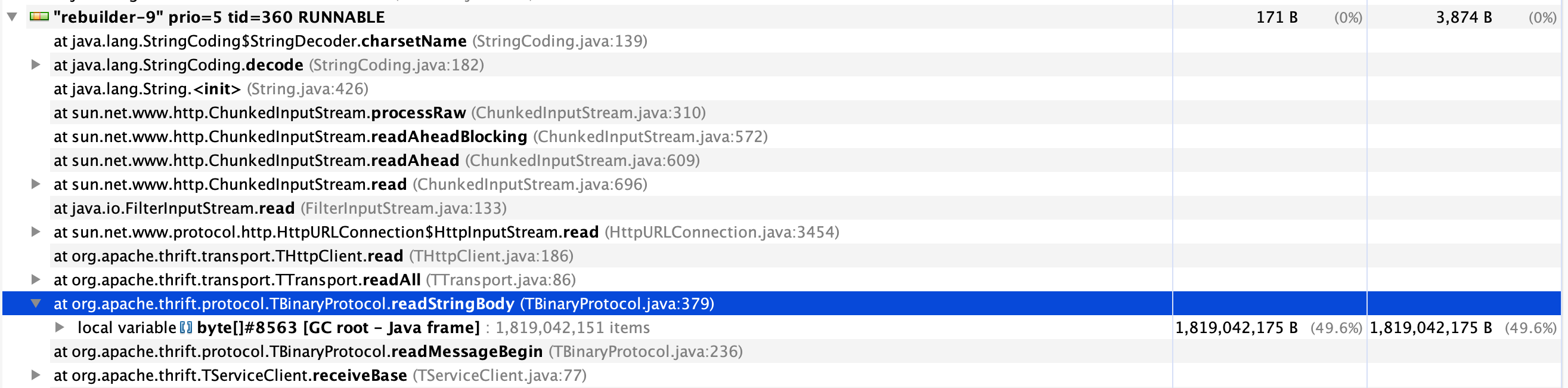
业务上遇到一个坑,java服务代理了一个接口到upstream,原样转发请求数据和头部。但是代理之后的结果总是莫名其妙的多了一个Cookie,比如是Set-Cookie: ticket=t1。
业务上用一个静态的AsyncHttpClient来做代理,也没有做特殊处理,基本上就是如下的代码逻辑:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| import org.asynchttpclient.*;
import java.io.IOException;
import java.util.concurrent.ExecutionException;
class Main {
private static AsyncHttpClient httpClient;
static {
DefaultAsyncHttpClientConfig.Builder builder = new DefaultAsyncHttpClientConfig.Builder();
httpClient = new DefaultAsyncHttpClient(builder.build());
}
public static void main(String[] args) throws ExecutionException, InterruptedException, IOException {
BoundRequestBuilder builder = httpClient.prepareGet(
"https://httpbin.org/cookies/set/ticket/val1"
);
builder.resetCookies();
builder.execute().get();
BoundRequestBuilder builder2 = httpClient.prepareGet(
"https://httpbin.org/cookies"
);
builder2.resetCookies();
Response res2 = builder2.execute().get();
System.out.println(res2.getResponseBody());
}
}
|
当时为了防止Cookie问题,特意加上了resetCookies。
首先是查看ticket Cookie的来源,发现upstream在客户端请求带上ticket Cookie的时候,会返回Set-Cookie: ticket=<val> 这个应该就是多余Cookie的来源了。
但是,即使客户端不带Cookie,java服务这边也会返回Set-Cookie字段。这个问题,排查之后发现问题在于resetCookies只能reset本次请求的Cookie,而客户端的Cookie,则不能清除。
即,某次请求,upstream返回了Set-Cookie: ticket=val,那么,以后的代理请求中,都会带上这个Cookie,那么最终用户也会拿到Set-Cookie字段……
从上述代码的运行结果也可以看出:
1
2
3
4
5
| {
"cookies": {
"ticket": "val1"
}
}
|
即,async-http-client没有一个request级别的Cookie控制,只能全局控制Cookie存储。这个问题也有人反馈给了async-http-client。