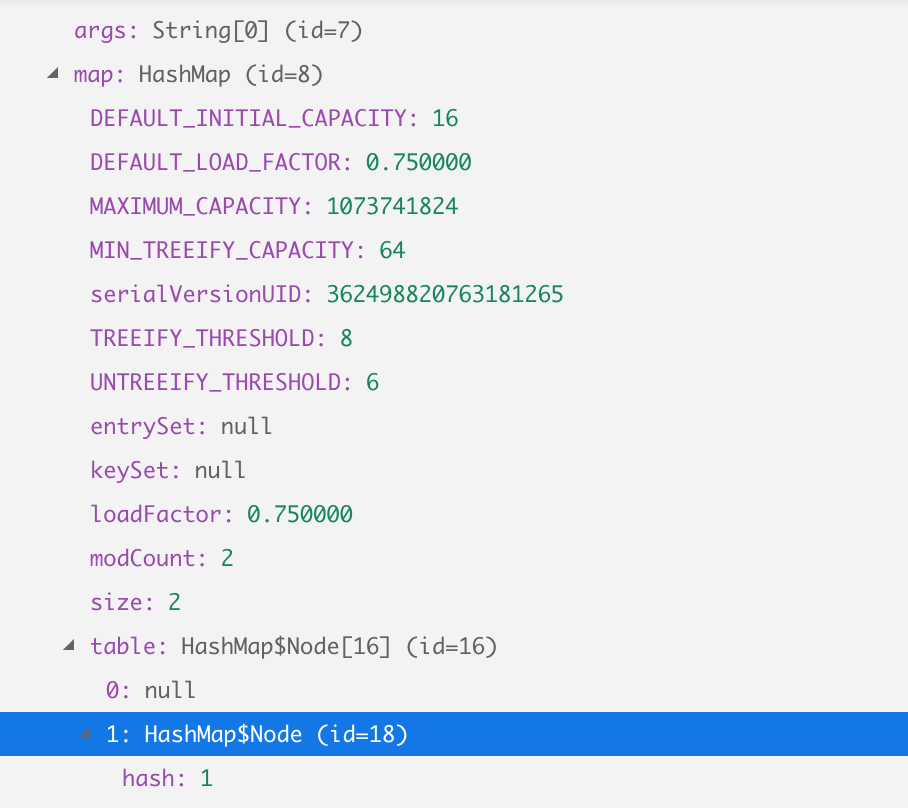
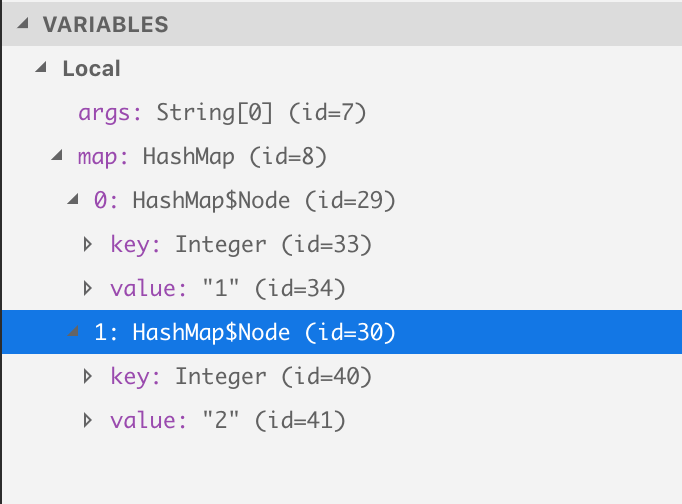
// If we receive any non ECONNREFUSED error, it means the port is used but we cannot connect if (err.code !== 'ECONNREFUSED') { returndoFindFreePort(startPort + 1, giveUpAfter - 1, clb); }
// Otherwise it means the port is free to use! returnclb(startPort); });
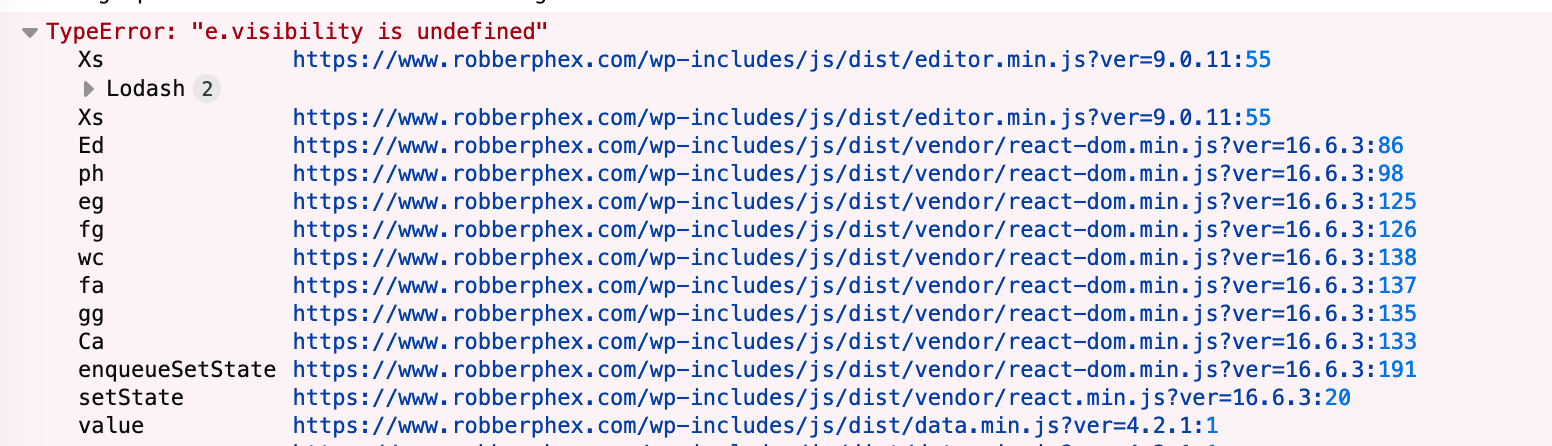
HTTP “Content-Type” of “video/mp4” is not supported. Load of media resource https://example.com/incorrect\_feedback.mp4 failed. VIDEOJS: ERROR: (CODE:4 MEDIA_ERR_SRC_NOT_SUPPORTED) No compatible source was found for this media.
To allow developers to customize the appearance of content returned to a Web client when a servlet generates an error, the deployment descriptor defines a list of error page descriptions. The syntax allows the configuration of resources to be returned by the container either when a servlet or filter calls sendError on the response for specific status codes, or if the servlet generates an exception or error that propagates to the container.
If the sendError method is called on the response, the container consults the list of error page declarations for the Web application that use the status-code syntax and attempts a match. If there is a match, the container returns the resource as indicated by the location entry.
The Web application may have declared error pages using the exception-typeelement. In this case the container matches the exception type by comparing the exception thrown with the list of error-page definitions that use the exception-typeelement. A match results in the container returning the resource indicated in the location entry. The closest match in the class hierarchy wins.